반응형
크롤링을 위해서 게시물에서 href link를 찾는 코드를 만들었습니다.
import requests
from bs4 import BeautifulSoup
def get_ad_link(data):
response = requests.get(data)
soup = BeautifulSoup(response.content, "html.parser")
link_data = []
find_Ads = soup.find_all('a', class_="href")
for find_Ad in find_Ads:
text = find_Ad.get_text(strip=True)
link_data.append(text)
print(link_data)
return link_data
여기서 <a> 속성의 href로 링크들을 모아올려고했습니다.
find_Ads = soup.find_all('a', class_="href")하지만 아무런 값을 가져오지 못했습니다. (LoL)
무려 chatGPT가 가르쳐준 코드인데....
답답한 마음에 google Gemini에게 물어봤습니다.. 근데.. 앗!
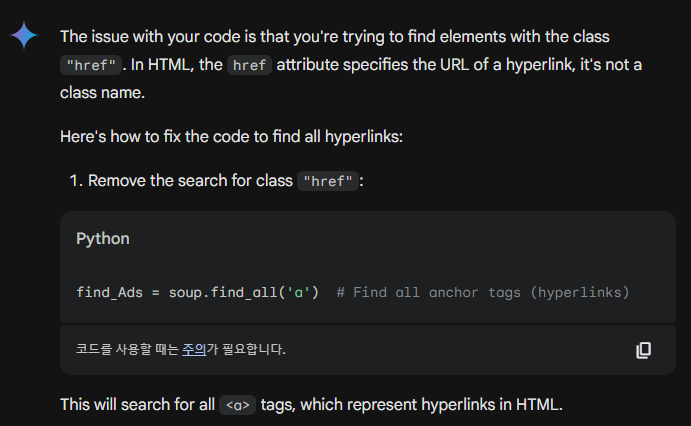

그렇습니다. HTML 코드에서 HREF는 CLASS가 아닌 속성입니다.
마음이 급해서 class_="href"를 넣었습니다.
따라서 href link 를 가져오기 위해서는 아래와 같이 코드가 만들어 져야 합니다. (GEMINI 대답)
def get_ad_link(data)
response = requests.get(data)
response.raise_for_status() # Raise an exception for non-2xx status codes
soup = BeautifulSoup(response.content, 'html.parser')
# Find all anchor tags (hyperlinks)
links = soup.find_all('a')
# Extract potential ad links
# Links pointing to Naver domains (heuristic approach)
ad_link_texts = []
for link in links:
text = link.get_text(strip=True)
if "naver.com" in link.get('href', ''):
ad_link_texts.append(text)
print(f"Potential ad link text: {text}") # Print for debugging/analysis
return ad_link_texts
반응형
'Engineering > Python' 카테고리의 다른 글
| [AI coding Tool] Cursor - 업무효율을 위한 궁극의 툴 (4) | 2024.09.18 |
|---|---|
| [python] docstring(주석)을 넣어 코드를 쉽게 봅시다. ( #, ''') (1) | 2024.04.28 |
| [Python] chrome-driver 업데이트 문제 해결하기 (0) | 2023.11.13 |
| [Python] IndexError: list index out of range (0) | 2023.05.27 |
| [python] 실시간 환율 가져오기 (feat. forex-python & xpath) (3) | 2023.05.05 |


댓글